2020

Egocentric Videoconferencing
Elgharib, M., Mendiratta, M., Thies, J., Nie/ssner, M., Seidel, H., Tewari, A., Vladislav Golyanik, , Theobalt, C.
Siggraph Asia, 2020 (article)
2019

SpoC: Spoofing Camera Fingerprints
Cozzolino, D., Thies, J., Rössler, A., Nießner, M., Verdoliva, L.
arXiv, 2019 (article)

Deferred Neural Rendering: Image Synthesis using Neural Textures
Thies, J., Zollhöfer, M., Nießner, M.
ACM Transactions on Graphics 2019 (TOG), 2019 (article)
2018
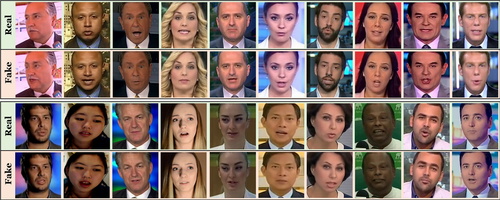
FaceForensics: A Large-scale Video Dataset for Forgery Detection in Human Faces
Rössler, A., Cozzolino, D., Verdoliva, L., Riess, C., Thies, J., Nießner, M.
arXiv, 2018 (article)

State of the Art on Monocular 3D Face Reconstruction, Tracking, and Applications
Zollhöfer, M., Thies, J., Bradley, D., Garrido, P., Beeler, T., Péerez, P., Stamminger, M., Nießner, M., Theobalt, C.
EG, 2018 (article)

Deep Video Portraits
Kim, H., Garrido, P., Tewari, A., Xu, W., Thies, J., Nießner, M., Péerez, P., Richardt, C., Zollhöfer, M., Theobalt, C.
ACM Transactions on Graphics 2018 (TOG), 2018 (article)

HeadOn: Real-time Reenactment of Human Portrait Videos
Thies, J., Zollhöfer, M., Stamminger, M., Theobalt, C., Nießner, M.
ACM Transactions on Graphics 2018 (TOG), 2018 (article)

ForensicTransfer: Weakly-supervised Domain Adaptation for Forgery Detection
Cozzolino, D., Thies, J., Rössler, A., Riess, C., Nießner, M., Verdoliva, L.
arXiv, 2018 (article)

FaceVR: Real-Time Gaze-Aware Facial Reenactment in Virtual Reality
Thies, J., Zollhöfer, M., Stamminger, M., Theobalt, C., Nießner, M.
ACM Transactions on Graphics 2018 (TOG), 2018 (article)
2016
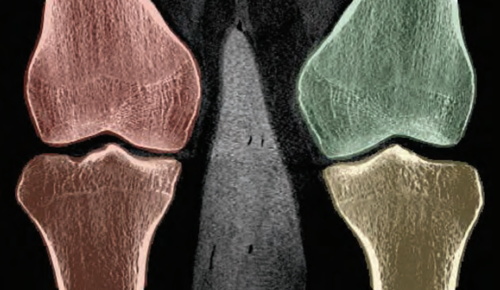
Marker-free motion correction in weight-bearing cone-beam CT of the knee joint
Berger, M., Müller, K., Aichert, A., Unberath, M., Thies, J., Choi, J., Fahrig, R., Maier, A.
Medical Physics, 43, pages: 1235-1248, 2016, UnivIS-Import:2017-12-18:Pub.2016.tech.IMMD.IMMD5.marker (article)
2015

Real-time Expression Transfer for Facial Reenactment
Thies, J., Zollhöfer, M., Nießner, M., Valgaerts, L., Stamminger, M., Theobalt, C.
ACM Transactions on Graphics (TOG), 34(6), ACM, 2015 (article)

Real-Time Pixel Luminance Optimization for Dynamic Multi-Projection Mapping
Siegl, C., Colaianni, M., Thies, L., Thies, J., Zollhöfer, M., Izadi, S., Stamminger, M., Frank, B.
ACM Transactions on Graphics (TOG), 34(6), ACM, 2015 (article)
2014

Interactive Model-based Reconstruction of the Human Head using an RGB-D Sensor
Zollhöfer, M., Thies, J., Colaianni, M., Stamminger, M., Greiner, G.
Computer Animation and Virtual Worlds, 25, pages: 213-222, 2014 (article)