2024

Stable Video Portraits

Synthesizing Environment-Specific People in Photographs
Ostrek, M., O’Sullivan, C., Black, M., Thies, J.
In European Conference on Computer Vision (ECCV 2024), LNCS, Springer Cham, European Conference on Computer Vision (ECCV 2024), October 2024 (inproceedings) Accepted

Text-Conditioned Generative Model of 3D Strand-based Human Hairstyles
Sklyarova, V., Zakharov, E., Hilliges, O., Black, M. J., Thies, J.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), CVPR 2024, June 2024 (inproceedings)
Neuropostors: Neural Geometry-aware 3D Crowd Character Impostors
Ostrek, M., Mitra, N. J., O’Sullivan, C.
In 2024 27th International Conference on Pattern Recognition (ICPR), Springer, 2024 27th International Conference on Pattern Recognition (ICPR), June 2024 (inproceedings) Accepted

TECA: Text-Guided Generation and Editing of Compositional 3D Avatars
Zhang, H., Feng, Y., Kulits, P., Wen, Y., Thies, J., Black, M. J.
In International Conference on 3D Vision (3DV 2024), 3DV 2024, March 2024 (inproceedings) To be published
GAN-Avatar: Controllable Personalized GAN-based Human Head Avatar
Kabadayi, B., Zielonka, W., Bhatnagar, B. L., Pons-Moll, G., Thies, J.
In International Conference on 3D Vision (3DV), March 2024 (inproceedings)
2023

Instant Volumetric Head Avatars
Zielonka, W., Bolkart, T., Thies, J.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), CVPR 2023, June 2023 (inproceedings)

MIME: Human-Aware 3D Scene Generation
Yi, H., Huang, C. P., Tripathi, S., Hering, L., Thies, J., Black, M. J.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages: 12965-12976, CVPR 2023, June 2023 (inproceedings) Accepted

DINER: Depth-aware Image-based Neural Radiance Fields
Prinzler, M., Hilliges, O., Thies, J.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), CVPR 2023, 2023 (inproceedings) Accepted
2022

Towards Metrical Reconstruction of Human Faces
Zielonka, W., Bolkart, T., Thies, J.
In Computer Vision – ECCV 2022, 13, pages: 250-269, Lecture Notes in Computer Science, 13673, (Editors: Avidan, Shai and Brostow, Gabriel and Cissé, Moustapha and Farinella, Giovanni Maria and Hassner, Tal), Springer, Cham, 17th European Conference on Computer Vision (ECCV 2022), October 2022 (inproceedings)

Human-Aware Object Placement for Visual Environment Reconstruction
Yi, H., Huang, C. P., Tzionas, D., Kocabas, M., Hassan, M., Tang, S., Thies, J., Black, M. J.
In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022), pages: 3949-3960, IEEE, Piscataway, NJ, IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022), June 2022 (inproceedings)

Neural Head Avatars from Monocular RGB Videos
Grassal, P., Prinzler, M., Leistner, T., Rother, C., Nießner, M., Thies, J.
In 2022 IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR) , pages: 18632-18643 , IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022), 2022 (inproceedings)
2021
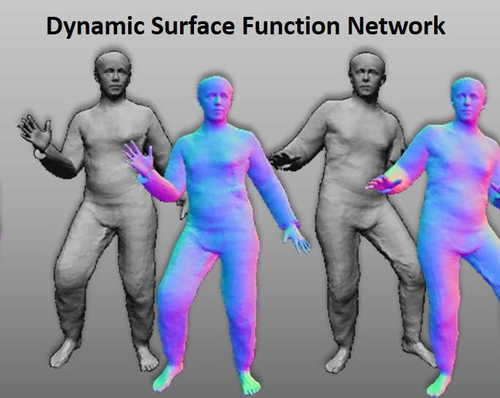
Dynamic Surface Function Networks for Clothed Human Bodies
Burov, A., Nießner, M., Thies, J.
In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages: 10734-10744, IEEE/CVF International Conference on Computer Vision (ICCV 2021), October 2021 (inproceedings)
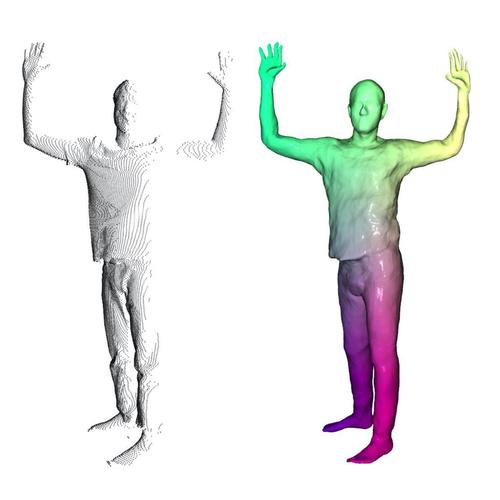
Neural Parametric Models for 3D Deformable Shapes
Palafox, P., Bozic, A., Thies, J., Nießner, M., Dai, A.
In 2021 IEEE/CVF International Conference on Computer Vision (ICCV 2021) , pages: 12675-12685 , IEEE, IEEE/CVF International Conference on Computer Vision (ICCV 2021) , October 2021 (inproceedings)
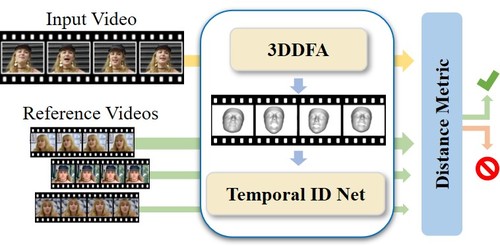
ID-Reveal: Identity-aware DeepFake Video Detection
Cozzolino, D., Rössler, A., Thies, J., Nießner, M., Verdoliva, L.
In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages: 15088-15097 , IEEE/CVF International Conference on Computer Vision (ICCV 2021), October 2021 (inproceedings)

RetrievalFuse: Neural 3D Scene Reconstruction with a Database
Siddiqui, Y., Thies, J., Ma, F., Shan, Q., Nießner, M., Dai, A.
In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages: 12548-12557 , IEEE/CVF International Conference on Computer Vision (ICCV 2021), October 2021 (inproceedings)

SpoC: Spoofing Camera Fingerprints
Cozzolino, D., Thies, J., Rössler, A., Nießner, M., Verdoliva, L.
In Workshop on Media Forensics (CVPR 2021), 2021 (inproceedings)

Neural Deformation Graphs for Globally-consistent Non-rigid Reconstruction
Bozic, A., Palafox, P., Zollöfer, M., Thies, J., Dai, A., Nießner, M.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages: 1450-1459 , IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2021), 2021 (inproceedings)

Dynamic Neural Radiance Fields for Monocular 4D Facial Avatar Reconstruction
Gafni, G., Thies, J., Zollöfer, M., Nießner, M.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), CVPR 2021, 2021 (inproceedings)
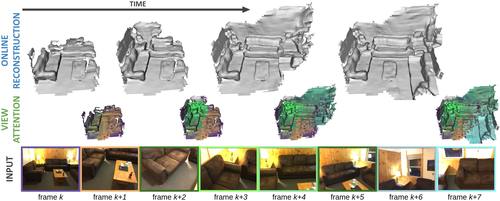
TransformerFusion: Monocular RGB Scene Reconstruction using Transformers
Bozic, A., Palafox, P., Thies, J., Dai, A., Nießner, M.
Advances in Neural Information Processing Systems 34 (NeurIPS 2021) , 2, pages: 1403-1414 , 35th Conference on Neural Information Processing Systems , 2021 (conference)

SPSG: Self-Supervised Photometric Scene Generation from RGB-D Scans
Dai, A., Siddiqui, Y., Thies, J., Valentin, J., Nießner, M.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), CVPR 2021, 2021 (inproceedings)

Neural RGB-D Surface Reconstruction
Azinovic, D., Martin-Brualla, R., Goldman, D. B., Nießner, M., Thies, J.
ArXiv, 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages: 6280-6291 , IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022), 2021 (conference)
2020

Neural Voice Puppetry: Audio-driven Facial Reenactment
Thies, J., Elgharib, M., Tewari, A., Theobalt, C., Nießner, M.
In Computer Vision – ECCV 2020, Springer International Publishing, Cham, August 2020 (inproceedings)

Adversarial Texture Optimization from RGB-D Scans
Huang, J., Thies, J., Dai, A., Kundu, A., Jiang, C., Guibas, L., Nießner, M., Funkhouser, T.
In Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), IEEE International Conference on Computer Vision and Pattern Recognition (CVPR) 2020, 2020 (inproceedings)

Egocentric Videoconferencing
Elgharib, M., Mendiratta, M., Thies, J., Nie/ssner, M., Seidel, H., Tewari, A., Vladislav Golyanik, , Theobalt, C.
Siggraph Asia, 2020 (article)

Neural Non-Rigid Tracking
Bozic, A., Palafox, P., Zollöfer, M., Dai, A., Thies, J., Nießner, M.
In NeurIPS, 2020 (inproceedings)

Intrinsic Autoencoders for Joint Neural Rendering and Intrinsic Image Decomposition
Alhaija, H. A., Mustikovela, S. K., Thies, J., Nießner, M., Geiger, A., Rother, C.
3DV, 2020 (conference)

Image-guided Neural Object Rendering
Thies, J., Zollhöfer, M., Theobalt, C., Stamminger, M., Nießner, M.
In International Conference on Learning Representations, 2020 (incollection)

State of the Art on Neural Rendering
Tewari, A., Fried, O., Thies, J., Sitzmann, V., Lombardi, S., Sunkavalli, K., Martin-Brualla, R., Simon, T., Saragih, J., Nießner, M., Pandey, R., Fanello, S., Wetzstein, G., Zhu, J., Theobalt, C., Agrawala, M., Shechtman, E., Goldman, D. B., Zollhöfer, M.
In EG, 2020 (inproceedings)

Learning Adaptive Sampling and Reconstruction for Volume Visualization
Weiss, S., Isik, M., Thies, J., Westermann, R.
IEEE Transactions on Visualization and Computer Graphics, pages: 1-1, 2020 (misc)
2019

DeepVoxels: Learning Persistent 3D Feature Embeddings
Sitzmann, V., Thies, J., Heide, F., Nießner, M., Wetzstein, G., Zollhöfer,
In Proc. Computer Vision and Pattern Recognition (CVPR), IEEE, 2019 (inproceedings)

SpoC: Spoofing Camera Fingerprints
Cozzolino, D., Thies, J., Rössler, A., Nießner, M., Verdoliva, L.
arXiv, 2019 (article)

FaceForensics++: Learning to Detect Manipulated Facial Images
Rössler, A., Cozzolino, D., Verdoliva, L., Riess, C., Thies, J., Nießner, M.
In ICCV 2019, 2019 (inproceedings)

Deferred Neural Rendering: Image Synthesis using Neural Textures
Thies, J., Zollhöfer, M., Nießner, M.
ACM Transactions on Graphics 2019 (TOG), 2019 (article)
2018
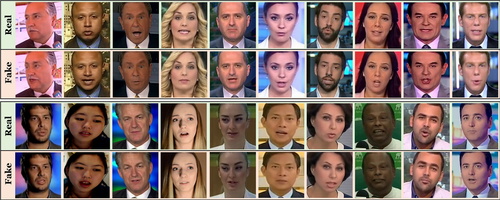
FaceForensics: A Large-scale Video Dataset for Forgery Detection in Human Faces
Rössler, A., Cozzolino, D., Verdoliva, L., Riess, C., Thies, J., Nießner, M.
arXiv, 2018 (article)

InverseFaceNet: Deep Monocular Inverse Face Rendering
Kim, H., Zollhöfer, M., Tewari, A., Thies, J., Richardt, C., Theobalt, C.
In Conference on Computer Vision and Pattern Recognition (CVPR), 2018 (inproceedings)

State of the Art on Monocular 3D Face Reconstruction, Tracking, and Applications
Zollhöfer, M., Thies, J., Bradley, D., Garrido, P., Beeler, T., Péerez, P., Stamminger, M., Nießner, M., Theobalt, C.
EG, 2018 (article)

Deep Video Portraits
Kim, H., Garrido, P., Tewari, A., Xu, W., Thies, J., Nießner, M., Péerez, P., Richardt, C., Zollhöfer, M., Theobalt, C.
ACM Transactions on Graphics 2018 (TOG), 2018 (article)

HeadOn: Real-time Reenactment of Human Portrait Videos
Thies, J., Zollhöfer, M., Stamminger, M., Theobalt, C., Nießner, M.
ACM Transactions on Graphics 2018 (TOG), 2018 (article)

ForensicTransfer: Weakly-supervised Domain Adaptation for Forgery Detection
Cozzolino, D., Thies, J., Rössler, A., Riess, C., Nießner, M., Verdoliva, L.
arXiv, 2018 (article)

FaceVR: Real-Time Gaze-Aware Facial Reenactment in Virtual Reality
Thies, J., Zollhöfer, M., Stamminger, M., Theobalt, C., Nießner, M.
ACM Transactions on Graphics 2018 (TOG), 2018 (article)
2017

Face2Face: Real-time Facial Reenactment

FaceForge: Markerless Non-Rigid Face Multi-Projection Mapping
Siegl, C., Lange, V., Stamminger, M., Bauer, F., Thies, J.
In IEEE Transactions on Visualization & Computer Graphics, 2017 (inproceedings)
2016

Face2Face: Real-time Face Capture and Reenactment of RGB Videos
Thies, J., Zollhöfer, M., Stamminger, M., Theobalt, C., Nießner, M.
In Proc. Computer Vision and Pattern Recognition (CVPR), IEEE, 2016 (inproceedings)
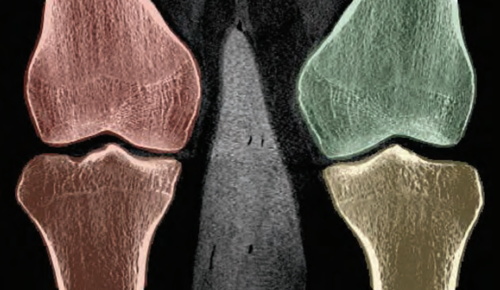
Marker-free motion correction in weight-bearing cone-beam CT of the knee joint
Berger, M., Müller, K., Aichert, A., Unberath, M., Thies, J., Choi, J., Fahrig, R., Maier, A.
Medical Physics, 43, pages: 1235-1248, 2016, UnivIS-Import:2017-12-18:Pub.2016.tech.IMMD.IMMD5.marker (article)
2015

Real-time Expression Transfer for Facial Reenactment
Thies, J., Zollhöfer, M., Nießner, M., Valgaerts, L., Stamminger, M., Theobalt, C.
ACM Transactions on Graphics (TOG), 34(6), ACM, 2015 (article)

Real-Time Pixel Luminance Optimization for Dynamic Multi-Projection Mapping
Siegl, C., Colaianni, M., Thies, L., Thies, J., Zollhöfer, M., Izadi, S., Stamminger, M., Frank, B.
ACM Transactions on Graphics (TOG), 34(6), ACM, 2015 (article)
2014

Interactive Model-based Reconstruction of the Human Head using an RGB-D Sensor
Zollhöfer, M., Thies, J., Colaianni, M., Stamminger, M., Greiner, G.
Computer Animation and Virtual Worlds, 25, pages: 213-222, 2014 (article)

