2021
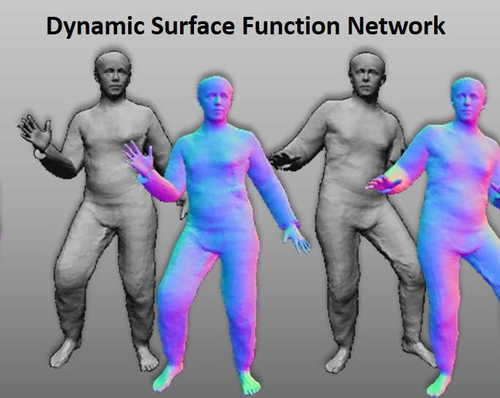
Dynamic Surface Function Networks for Clothed Human Bodies
Burov, A., Nießner, M., Thies, J.
In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages: 10734-10744, IEEE/CVF International Conference on Computer Vision (ICCV 2021), October 2021 (inproceedings)
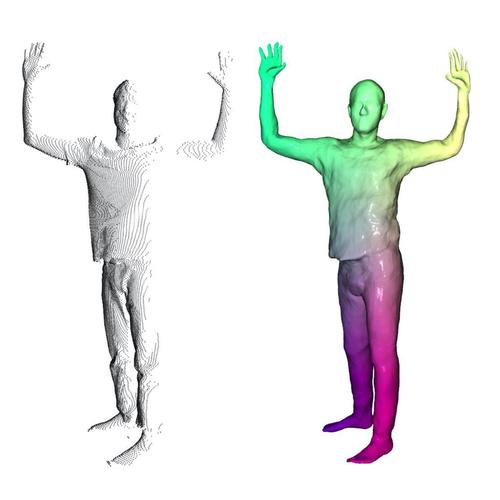
Neural Parametric Models for 3D Deformable Shapes
Palafox, P., Bozic, A., Thies, J., Nießner, M., Dai, A.
In 2021 IEEE/CVF International Conference on Computer Vision (ICCV 2021) , pages: 12675-12685 , IEEE, IEEE/CVF International Conference on Computer Vision (ICCV 2021) , October 2021 (inproceedings)
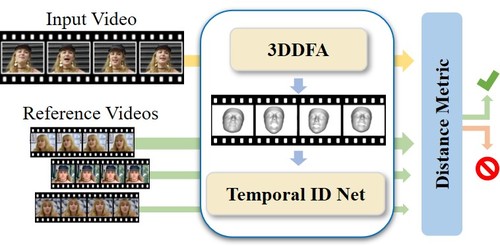
ID-Reveal: Identity-aware DeepFake Video Detection
Cozzolino, D., Rössler, A., Thies, J., Nießner, M., Verdoliva, L.
In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages: 15088-15097 , IEEE/CVF International Conference on Computer Vision (ICCV 2021), October 2021 (inproceedings)

RetrievalFuse: Neural 3D Scene Reconstruction with a Database
Siddiqui, Y., Thies, J., Ma, F., Shan, Q., Nießner, M., Dai, A.
In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages: 12548-12557 , IEEE/CVF International Conference on Computer Vision (ICCV 2021), October 2021 (inproceedings)

SpoC: Spoofing Camera Fingerprints
Cozzolino, D., Thies, J., Rössler, A., Nießner, M., Verdoliva, L.
In Workshop on Media Forensics (CVPR 2021), 2021 (inproceedings)

Neural Deformation Graphs for Globally-consistent Non-rigid Reconstruction
Bozic, A., Palafox, P., Zollöfer, M., Thies, J., Dai, A., Nießner, M.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages: 1450-1459 , IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2021), 2021 (inproceedings)

Dynamic Neural Radiance Fields for Monocular 4D Facial Avatar Reconstruction
Gafni, G., Thies, J., Zollöfer, M., Nießner, M.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), CVPR 2021, 2021 (inproceedings)
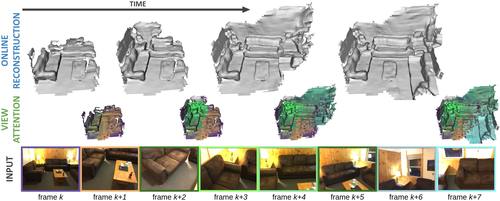
TransformerFusion: Monocular RGB Scene Reconstruction using Transformers
Bozic, A., Palafox, P., Thies, J., Dai, A., Nießner, M.
Advances in Neural Information Processing Systems 34 (NeurIPS 2021) , 2, pages: 1403-1414 , 35th Conference on Neural Information Processing Systems , 2021 (conference)

SPSG: Self-Supervised Photometric Scene Generation from RGB-D Scans
Dai, A., Siddiqui, Y., Thies, J., Valentin, J., Nießner, M.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), CVPR 2021, 2021 (inproceedings)

Neural RGB-D Surface Reconstruction
Azinovic, D., Martin-Brualla, R., Goldman, D. B., Nießner, M., Thies, J.
ArXiv, 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages: 6280-6291 , IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022), 2021 (conference)