2024

Stable Video Portraits

Synthesizing Environment-Specific People in Photographs
Ostrek, M., O’Sullivan, C., Black, M., Thies, J.
In European Conference on Computer Vision (ECCV 2024), LNCS, Springer Cham, European Conference on Computer Vision (ECCV 2024), October 2024 (inproceedings) Accepted

Text-Conditioned Generative Model of 3D Strand-based Human Hairstyles
Sklyarova, V., Zakharov, E., Hilliges, O., Black, M. J., Thies, J.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), CVPR 2024, June 2024 (inproceedings)
Neuropostors: Neural Geometry-aware 3D Crowd Character Impostors
Ostrek, M., Mitra, N. J., O’Sullivan, C.
In 2024 27th International Conference on Pattern Recognition (ICPR), Springer, 2024 27th International Conference on Pattern Recognition (ICPR), June 2024 (inproceedings) Accepted

TECA: Text-Guided Generation and Editing of Compositional 3D Avatars
Zhang, H., Feng, Y., Kulits, P., Wen, Y., Thies, J., Black, M. J.
In International Conference on 3D Vision (3DV 2024), 3DV 2024, March 2024 (inproceedings) To be published
GAN-Avatar: Controllable Personalized GAN-based Human Head Avatar
Kabadayi, B., Zielonka, W., Bhatnagar, B. L., Pons-Moll, G., Thies, J.
In International Conference on 3D Vision (3DV), March 2024 (inproceedings)
2023

Instant Volumetric Head Avatars
Zielonka, W., Bolkart, T., Thies, J.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), CVPR 2023, June 2023 (inproceedings)

MIME: Human-Aware 3D Scene Generation
Yi, H., Huang, C. P., Tripathi, S., Hering, L., Thies, J., Black, M. J.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pages: 12965-12976, CVPR 2023, June 2023 (inproceedings) Accepted

DINER: Depth-aware Image-based Neural Radiance Fields
Prinzler, M., Hilliges, O., Thies, J.
In IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), CVPR 2023, 2023 (inproceedings) Accepted
2022

Towards Metrical Reconstruction of Human Faces
Zielonka, W., Bolkart, T., Thies, J.
In Computer Vision – ECCV 2022, 13, pages: 250-269, Lecture Notes in Computer Science, 13673, (Editors: Avidan, Shai and Brostow, Gabriel and Cissé, Moustapha and Farinella, Giovanni Maria and Hassner, Tal), Springer, Cham, 17th European Conference on Computer Vision (ECCV 2022), October 2022 (inproceedings)

Human-Aware Object Placement for Visual Environment Reconstruction
Yi, H., Huang, C. P., Tzionas, D., Kocabas, M., Hassan, M., Tang, S., Thies, J., Black, M. J.
In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022), pages: 3949-3960, IEEE, Piscataway, NJ, IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022), June 2022 (inproceedings)

Neural Head Avatars from Monocular RGB Videos
Grassal, P., Prinzler, M., Leistner, T., Rother, C., Nießner, M., Thies, J.
In 2022 IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR) , pages: 18632-18643 , IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022), 2022 (inproceedings)
2021
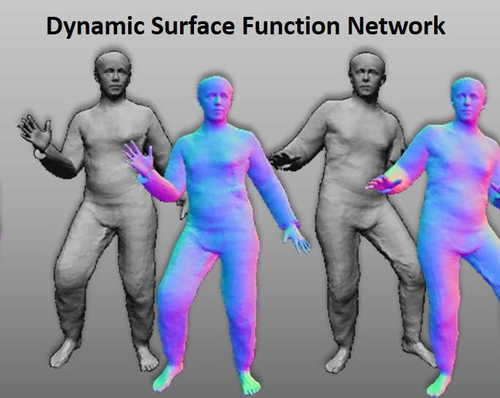
Dynamic Surface Function Networks for Clothed Human Bodies
Burov, A., Nießner, M., Thies, J.
In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages: 10734-10744, IEEE/CVF International Conference on Computer Vision (ICCV 2021), October 2021 (inproceedings)
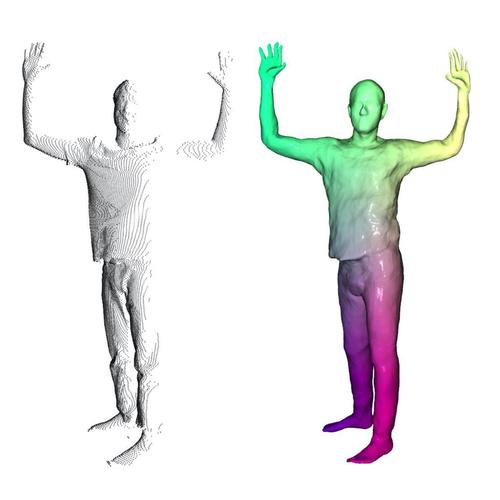
Neural Parametric Models for 3D Deformable Shapes
Palafox, P., Bozic, A., Thies, J., Nießner, M., Dai, A.
In 2021 IEEE/CVF International Conference on Computer Vision (ICCV 2021) , pages: 12675-12685 , IEEE, IEEE/CVF International Conference on Computer Vision (ICCV 2021) , October 2021 (inproceedings)
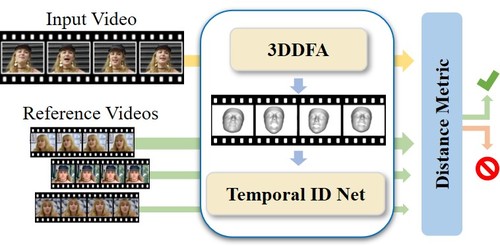
ID-Reveal: Identity-aware DeepFake Video Detection
Cozzolino, D., Rössler, A., Thies, J., Nießner, M., Verdoliva, L.
In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages: 15088-15097 , IEEE/CVF International Conference on Computer Vision (ICCV 2021), October 2021 (inproceedings)

RetrievalFuse: Neural 3D Scene Reconstruction with a Database
Siddiqui, Y., Thies, J., Ma, F., Shan, Q., Nießner, M., Dai, A.
In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages: 12548-12557 , IEEE/CVF International Conference on Computer Vision (ICCV 2021), October 2021 (inproceedings)
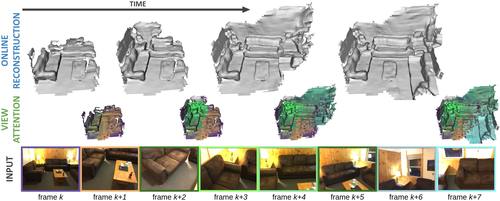
TransformerFusion: Monocular RGB Scene Reconstruction using Transformers
Bozic, A., Palafox, P., Thies, J., Dai, A., Nießner, M.
Advances in Neural Information Processing Systems 34 (NeurIPS 2021) , 2, pages: 1403-1414 , 35th Conference on Neural Information Processing Systems , 2021 (conference)

Neural RGB-D Surface Reconstruction
Azinovic, D., Martin-Brualla, R., Goldman, D. B., Nießner, M., Thies, J.
ArXiv, 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages: 6280-6291 , IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022), 2021 (conference)

